




Schlagwortkatalogisierung im Wandel der Zeit
Wir schreiben das Jahr 1983 und gehen in die Deutsche Bücherei in Leipzig, um Literatur über „Recycling“ zu finden und finden circa 20 Ressourcen mit dem Schlagwort „Recycling“.
Ein Blick in den Katalog der Deutschen Bibliothek in Frankfurt am Main durch Freunde zur selben Zeit ergibt gar keinen Treffer. Die Suche mit dem Schlagwort „Abfallverwertung“ dagegen bringt insgesamt etwa 130 Treffer in beiden Bibliotheken.
Heute im Frühjahr 2022 finden wir unter dem Schlagwort „Recycling“ über 1700 erschlossene Ressourcen.
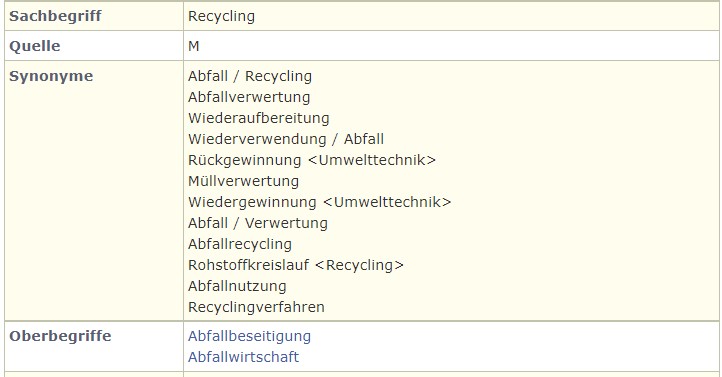
Woher kommt der große Unterschied?
Die alten Schlagwörter waren reine Textphrasen, keine Normdatensätze. Es gab damals unterschiedliche Schlagwörter wie Abfallverwertung, Rückgewinnung, Wiederverwendung, Müllverwertung und weitere, die alle einzeln gesucht werden mussten. Heute sind sie, da der Bedeutungsunterschied so gering ist, alle in einem Normdatensatz zusammengeführt und mit welchem Suchwort auch immer („Recycling“ oder „Abfallverwertung“ oder …) die Suche durchgeführt wird, man bekommt alle Ressourcen zu diesem Thema. Dass sich 1983 die Schlagwortvergabe für die Nationalbibliografie in Leipzig mit „Recycling“ als „westlicher“ herausstellen und am Ende durchsetzen sollte, belegt nur, dass sich sprachliche Entwicklungen kaum vorhersehen, geschweige denn steuern lassen können.
Allgemeines zur Schlagwortkatalogisierung und ihrem Anspruch
Die Schlagwortkatalogisierung benutzt die natürliche Sprache und Sprache wandelt sich im Laufe der Zeit einschließlich ihrer Orthografie. Hier sind einige Beispiele: Abfallverwertung (alt) – Recycling (neu); Fremdenverkehr (alt) – Tourismus (neu); spulen (alt) – scrollen (neu); Felsengebirge (alt) – Rocky Mountains (neu); Eingeborene (alt) – Indigene Völker (neu); Potential (alt) – Potenzial (neu); Bibliographie (alt) – Bibliografie (neu). Auch die Bedeutung und Akzeptanz von Wörtern kann nach einigen Jahrzehnten eine andere sein beziehungsweise wird regional unterschiedlich bewertet. Ich bin in Nordrhein-Westfalen zur Schule gegangen. Man sprach nur von „Jungen“ oder „Jungs“; in Hessen gibt es „Buben“ und zwar nicht im Sinne von „Spitzbuben“. Der „Knabe“ entspricht dem „Jungen“, gehört aber heute nicht mehr zu unserem alltäglichen Sprachgebrauch, wird dagegen in der älteren Literatur oft verwendet. Schlagwortkatalogisierung sollte immer neutral sein. Das heißt, dass das Indexierungsvokabular vorurteilsfrei und unparteiisch sein sollte. Und das Vokabular sollte immer aktuell sein. Wie können die genannten Ziele der Neutralität und Aktualität bei Bibliotheken mit einer langen Tradition erreicht werden? Historische Sacherschließung (mit welchen Methoden auch immer), die heute in Online-Katalogen sichtbar ist, ist nicht selbsterklärend und führt zu Rückfragen.
Schlagwortkatalogisierung in der DNB – ein kurzer historischer Rückblick
Bis 1990 gab es zwei getrennte Einrichtungen in Leipzig und Frankfurt am Main. Jede Bibliothek hatte ihr eigenes System mit unterschiedlichen Vokabularien, getrennten Bibliografien und getrennten Katalogen. Viele Jahre gab es keine Normdatei; es wurden keine Normdatensätze, sondern nur reine Textphrasen benutzt. Das heißt, dass die Einträge in den bibliografischen Beschreibungen nicht mit Normdaten verlinkt, sondern einfache Textstrings waren.
In Frankfurt am Main wurde seit 1986 eine Normdatei, die Schlagwortnormdatei (SWD), eingesetzt.
Heute ist die DNB eine Bibliothek mit zwei Standorten. Es gibt nur noch einen gemeinsamen Katalog mit gemeinsamen Regeln, den „Regeln für die Schlagwortkatalogisierung (RSWK)“. Für die Schlagwortkatalogisierung werden Normdatensätze aus einer Normdatei, der Gemeinsamen Normdatei (GND), benutzt. Die Einträge in der bibliografischen Beschreibung sind Links zu Normdatensätzen. Beispiele:
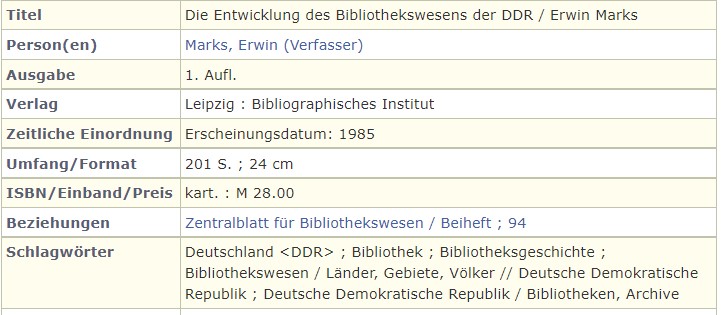

Schlagwortkatalogisierung mit Normdaten
Schlagwortkatalogisierung mit Normdaten hat sehr große Vorteile gegenüber einfachen Textphrasen. Normdatensätze werden beständig gepflegt. Das bedeutet, dass veraltete Benennungen aktualisiert oder kritische Benennungen erklärt werden, wenn es notwendig ist, sie beizubehalten, um ältere Literatur auffindbar zu machen. Sie werden in der Recherche für den Zeitraum, in dem sie gesellschaftlich akzeptiert waren und als Schlagwörter benutzt wurden, weiterhin als Sucheinstiege erwartet. Deshalb sollte die terminologische Entwicklung bei älteren inhaltlich-erschlossenen Titeln dokumentiert werden.
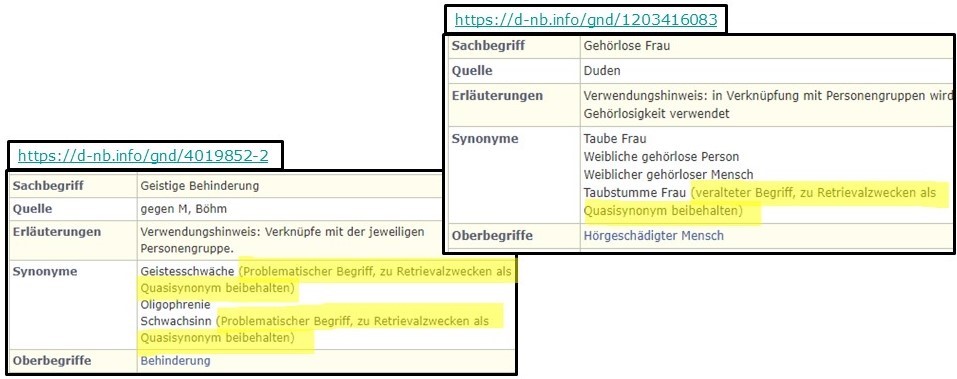
Die Normdatensätze sind in der bibliografischen Beschreibung der Medienwerke als Link zum Normdatensatz eingetragen.
Korrekturen an Normdatensätzen sind sofort in der bibliografischen Beschreibung sichtbar; das heißt die Schlagworteinträge entsprechen immer dem aktuellen Stand. Auf diese Weise spiegelt die Sacherschließung immer den augenblicklichen terminologischen Sachverhalt und die derzeitigen wissenschaftlichen und gesellschaftlichen Sichten wider. Rückfragen und Irritationen werden so vermieden, die zurzeit bezogen auf die historischen Schlagwörter der DNB die Abteilung Inhaltserschließung von Zeit zu Zeit erreichen.
Deshalb sollen die historischen Schlagwörter aus der Vergangenheit der DNB soweit wie möglich in Normdatensätze überführt werden. Dafür wurde ein DNB-internes Vorhaben gestartet.
Überführung von historischen Schlagwörtern in heutige GND-Schlagwörter (Normdaten)
Das Vorhaben umfasst verschiedene Aufgaben: Zunächst mussten die historischen Schlagwörter gesammelt und auf die heutigen GND-Normdaten abgebildet oder „gemappt“ werden. Danach sollen die Titelaufnahmen der betreffenden Ressourcen jeweils um diese GND-Normdaten angereichert werden. Die historischen Schlagwörter sollen in der internen Katalogdatenbank beibehalten werden, aber nicht mehr im öffentlichen Katalog der DNB in Erscheinung treten und auch nicht länger recherchierbar sein. Für die historische Forschung und die Digital Humanities sind die alten Erschließungen eine Fundgrube.
In einem ersten Schritt wurden die Daten analysiert: Circa 700.000 Titel sind betroffen mit durchschnittlich drei Schlagwörtern pro Titel.
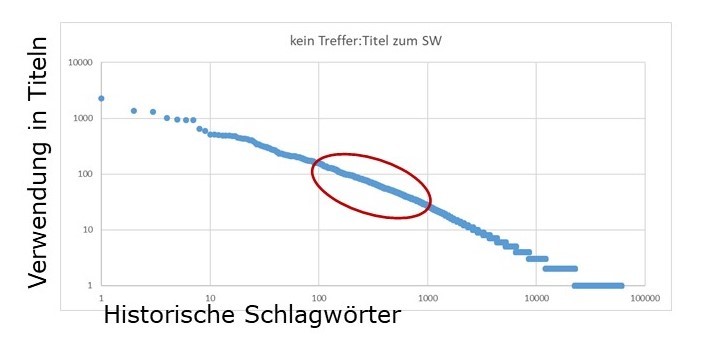
Insgesamt handelt es sich um rund 169.000 verschiedene historische Schlagwörter, eine sehr hohe Zahl; allerdings sind ihre tatsächliche zahlenmäßige Verwendung und damit ihre Wichtigkeit sehr unterschiedlich: 80.000 von ihnen wurden nur einmal, 65.000 zwei bis neunmal und 24.000 zehnmal und häufiger verwendet. Das sind die Zahlen im Einzelnen:
7750 verschiedene Schlagwörter decken 70 Prozent der Titel ab
2280 verschiedene Schlagwörter decken 50 Prozent der Titel ab
1000 verschiedene Schlagwörter decken 37 Prozent der Titel ab
500 verschiedene Schlagwörter decken 27 Prozent der Titel ab
100 verschiedene Schlagwörter decken 12,5 Prozent der Titel ab Mit 2280 verschiedenen Schlagwörtern, das entspricht nur 1,3 Prozent der Gesamtmenge der 169.000 historischen Schlagwörter, sind bereits 50 Prozent der betroffenen Titel erschlossen.

Die Datenanalyse stimmte hoffnungsfroh, mit einem überschaubaren Aufwand ein gutes Ergebnis zu bekommen. Also wurden die historischen Schlagwörter in einer Exceltabelle gesammelt und über einen einfachen Abgleich der Textphrasen mit den bevorzugten und abweichenden Benennungen der Normdatensätze für Sachschlagwörter und Geografika maschinell zu GND-Normdatensätzen gemappt. Normdatensätze für Personen haben eine eigene Struktur; außerdem ist das Segment der Personennormdatensätze das umfangreichste in der GND. Deshalb musste für die historischen Personenschlagwörter ein eigener Abgleichlauf konzipiert und durchgeführt werden.
Der automatische Abgleich war erfolgreich: Circa 108.000 historische Schlagwörter konnten automatisch zu GND-Schlagwörtern gemappt werden – das sind 64 Prozent aller historischen Schlagwörter. Damit waren bereits 90 Prozent der Titel abgedeckt. Für die wichtigsten, das heißt am häufigsten verwendeten Schlagwörter wurde das Mapping intellektuell überprüft. Insgesamt wurden über 12.000 Mappings intellektuell durchgesehen.
Circa 61.000 historische Schlagwörter (36 Prozent aller historischen Schlagwörter) konnten nicht automatisch gemappt werden. Allerdings deckten diese 36 Prozent der Schlagwörter nur 10 Prozent der Titel ab, da sie meistens nur einmal verwendet wurden. Schlagwörter, die häufig verwendet wurden, aber nicht automatisch gemappt werden konnten, wurden intellektuell zugeordnet.
Die Überprüfung des automatischen Mappings sowie die Erstellung des intellektuellen Mappings für die Schlagwörter, die nicht maschinell abgebildet werden konnten, wurde von den Mitarbeitenden der Abteilung Inhaltserschließung verteilt nach fachlichen Zuständigkeiten durchgeführt. Bei Fehlern des automatischen Mappings wurden die zutreffenden Normdatennummern in die Exceltabelle geschrieben. Aus dieser Arbeits-Exceltabelle wurde für die technische Umsetzung durch die IT-Abteilung der DNB eine saubere Exceltabelle mit der Textphrase des historischen Schlagworts zugeordnet zu der GND-Normnummer für das aktuell verwendete Schlagwort erstellt. Bevor die Katalogdaten im Produktivsystem geändert werden, soll eine Umsetzung im Approvalsystem erfolgen mit einer anschließenden Testphase durch die Abteilung Inhaltserschließung.

Historische Schlagwörter sind Normdatensätzen zugeordnet.
Die GND-Schlagwörter sollen in das wiederholbare PICA-Feld 5550 geschrieben werden, in dem GND-Normdatensätze aus Fremddaten oder aus Konkordanzprojekten (zum Beispiel Konkordanzprojekt Standard-Thesaurus-Wirtschaft zur GND) eingetragen werden. Dabei wird die Herkunft dieser GND-Schlagwörter nach den Festlegungen für die Herkunftskennung wie folgt gekennzeichnet:
$E (Erfassungsart): a – (= andere Erfassungsart)
$H (Herkunft): kasw (= Konkordanz alte Schlagwörter)
$K (Konfidenzwert): 1,000
$D (aktuelles Einspieldatum):
Für das Vorhaben wurden rund 12 Monate veranschlagt, was sich auch als realistisch erwiesen hat. Nach Beginn im Frühsommer 2021 mit den ersten Datenanalysen sollte das Vorhaben Ende des Frühjahrs 2022 abgeschlossen sein, getreu dem Motto „Alles neu macht der Mai …“. Infolge der Umsetzung der historischen Schlagwörter in GND-Schlagwörter wird nun ein großer Teil des Altbestandes besser auffindbar und zugänglich sein.
Technische Beschreibung der Datenanalysen (von Christian Baumann)
Durch die Zusammenführung zweier Schlagwortsysteme mit unterschiedlichen Traditionen der Normierung ergaben sich einige Schwierigkeiten, die hier kurz dargestellt werden sollen. Zu beachten ist außerdem, dass selbst innerhalb eines Katalogs (undokumentierte) Traditionsabbrüche und Verschreiber keine Seltenheit waren.
Zunächst wurden die Daten vorverarbeitet, bei den Altdaten eckige Klammern (West) auf runde Klammern (Ost) normiert und die Unicode-Zerlegung (ë = e + ¨) vereinheitlicht. Auch die zum Abgleich benötigten GND-Daten wurden gefiltert, das heißt nur Daten mit Level 1 oder z und nur solche aus dem Teilbestand ‚s‘ (Sacherschließung) zugelassen.
Bei der Erfassung von Personennamen aus Sprachen mit nicht-lateinischen Alphabeten, insbesondere bei denen aus der ehemaligen Sowjetunion, gab es in Ost und West sehr unterschiedliche Traditionen. Beispielsweise wurde Nikita Sergeevič Chruščëv (heutige wissenschaftliche Transliteration) in Frankfurt am Main als „Chruschtschow, Nikita“, in Leipzig mal als „Chruschtschow, Nikita S.“, mal als „Chrustschow, Nikita S.“ wiedergegeben. Alle drei Schreibweisen finden sich als variante Namen am Datensatz <https://d-nb.info/gnd/118638378>. Es blieb daher nichts anderes übrig, als sicherheitshalber alle (in Chruschtschows Fall 81) Verweisungsformen in eine temporäre Datenbank zu überführen, um diese anschließend durchsuchen zu können.
Bei Sachschlagwörtern war zu beachten, dass man in Leipzig die Sacherschließungstermini bevorzugt im Plural erfasste, während in Frankfurt am Main das genau gegensätzliche Prinzip „Erfassung im Singular“ galt. So wurde in Frankfurt am Main „Naturstoff“, in Leipzig aber „Naturstoffe“ als Schlagwort gewählt. Die heutige GND folgt strikt der westdeutschen Tradition und verweist leider auch nicht den Plural als Synonym.
Daher musste eine eigenwillige Strategie beschritten werden: Wie bei den Personen wurde auch für Sachbegriffe und Geografika aus dem GND-Abzug eine Datenbank mit bevorzugter Benennung und Synonym-Verweisungen aufgebaut. Wurde in dieser Datenbank ein Hit erzielt, war man fertig. Andernfalls wurde der letzte Buchstabe des Suchworts entfernt und trunkiert gesucht (für Expert*innen: mithilfe eines Tries). Dieses Verfahren wurde wiederholt, bis Treffer erzielt wurden oder 60 Prozent der ursprünglichen Wortlänge erreicht waren. Naturgemäß liegt hier eine potentielle Fehlerquelle vor, da auch falsche oder zu viele Treffer auftreten können. Es war so aber immerhin möglich, „Abkühlungsvorgänge“ auf „Abkühlung“, „Nauheim (Bad)“ auf „Bad Nauheim“, ja sogar das falsch geschriebene „Kohärente Strahlund“ auf „Kohärente Strahlung“ zurückzuführen.
Am Ende mussten die verschiedenen Datenblätter, ob automatisiert oder intellektuell erstellt, zu einer einzigen Konkordanz zusammengeführt werden. Dazu wurden diese verschiedenen Datenquellen nach und nach in eine temporäre Datenbank (eine schlichte Hashmap) eingelesen. Es wurde mit der unzuverlässigsten Datenquelle begonnen und zu immer zuverlässigeren fortgeschritten. Trat im Verlauf dieses Prozesses ein Eintrag ein zweites Mal auf, konnte man sicher sein, dass der unzuverlässige von einen zuverlässigeren überschrieben wurde.