




Digitale Daten restaurieren
Die Digitalisierung schützt in vielen Bereichen Kulturgut vor dem Verfall. Bücher können so beschädigt sein, dass man sie nicht mehr durchblättern kann. Kunstwerke können so empfindlich sein, dass sie nur noch digital zugänglich gemacht werden können. Digitale Daten altern aber auch selbst. In diesem Beitrag erzählen wir, wie wir sehr alte digitale Daten restauriert haben, so dass sie jetzt wieder benutzt werden können.

Das Projekt „Inventar archivalischer Quellen“
Die Deutsche Nationalbibliothek hat in den 1990er-Jahren in einem Projekt mit vielen anderen Partnern die archivalischen Quellen zur Geschichte des deutschsprachigen Buchhandels im 19. und im 20. Jahrhundert recherchiert. Viele Jahre lang reisten wissenschaftliche Mitarbeiterinnen und Mitarbeiter durch ca. 580 Archive. Dort recherchierten sie alle Akten, in denen es um Themen rund um den Buchhandel ging: Akten zu Streiks im Buchgewerbe, zu einzelnen Buchhandlungen, zur Zensur oder zu Druck- und Verkaufsprivilegien. Ein Inventar verzeichnete alle gefundenen Akten.
Die Mitarbeiter*innen des Projektes sammelten insgesamt Belege zu mehr als 64.000 Akten. Um das Jahr 2000 beauftragte das Projektteam eine Web-Anwendung. In dieser Anwendung konnten Nutzer*innen die Daten durchsuchen, sie hatten verschiedene Register und Sucheinstiege zur Verfügung. Sowohl das Sammeln der Daten als auch die Web-Anwendung hatte die Deutsche Forschungsgemeinschaft als Projekte finanziert. Nach dem Ende der Projekte setzte sich niemand mehr aktiv für die Web-Anwendung oder die Daten ein. Sie waren irgendwie da, die Anwendung war online, niemand entwickelte sie aber mehr aktiv weiter, die Mitarbeiter*innen des Projektes widmeten sich anderen Aufgaben.
Zustandsbeschreibung vor der Restaurierung
Fast Forward, 20 Jahre später: die Web-Anwendung lebt noch immer auf ihrem alten Webserver. Die Programme der Betriebsumgebung sind hoffnungslos veraltet. Das System ist schlecht dokumentiert. Niemand weiß mehr ganz genau, wie das alles aufgebaut ist. Viele Funktionen der Web-Anwendung laufen nur noch fehlerhaft oder gar nicht mehr. Zwar gibt es die Firma noch, die seinerzeit die Anwendung programmiert hat. Doch auch dort weiß niemand mehr genau, wie die Datenbank strukturiert war. Das Projekt hatte keine Strategie zur Langzeitarchivierung. Es stammte aus einer Zeit, die zwar Web- und Datenstandards schon kannte. In diesen frühen Jahren probierten Menschen in Kultureinrichtungen aber auch oft aus, was digital möglich wäre. Proprietäre Anwendungen waren für sich genommen schick und neu, blieben aber oft für sich allein bestehen. Manche dieser Projekte entwickelten sich zu (manchmal freien) Softwareprojekten, zogen eine Community von Entwickler*innen und Nutzer*innen an.
Restaurierung der Daten
Wir mussten feststellen, dass wir die Daten nicht aus der alten kommerziellen SQL-Datenbank exportieren konnten. Die Datenstruktur war kryptisch und nicht nachzukonstruieren. Wir fanden keine technische Beschreibung des Systems und die SQL-Software funktionierte nicht mehr richtig. Also suchten wir einen anderen Weg. Wir fanden noch die alten Rohdaten. Die Projektmitarbeiter*innen hatten die Daten nach strengen Erfassungsregeln in Word-Dateien geschrieben. Diese Word-Dateien lasen wir mit einem selbstgeschriebenen Python-Skript aus und transformierten sie in das Format JSON (Java Script Objekt Notation).
Entitäten wie Personen, Körperschaften oder Orte waren in den Daten durch spezielle Tags markiert. Diese Tags lasen wir mit einem weiteren Skript aus den Daten aus und ordneten sie zu Registern im CSV-Format an. Wer mit diesen Registern arbeitet, kann diese nun in einem Tabellenkalkulationsprogramm öffnen, darin suchen, sie neu sortieren oder filtern.
Neuveröffentlichung der Daten
Die Daten liegen nun in einem Repository auf dem Code-Portal GitHub. Dort können sie von allen kostenlos heruntergeladen und angesehen werden. Alle Dateien haben außerdem eine URL, so dass man sie direkt in eigene Anwendungen importieren kann. In das Repository haben wir auch die Rohdaten und die Skripte gelegt, mit denen wir die Daten transformiert haben. So kann man nachvollziehen, was genau mit den Daten passiert ist.
Der Kern von GitHub ist die Möglichkeit zur Mitarbeit. Das Portal stellt zahlreiche Tools für die gemeinsame Arbeit an dem Repository zur Verfügung und es dokumentiert jede Veränderung oder Ergänzung.
FAIRe Daten
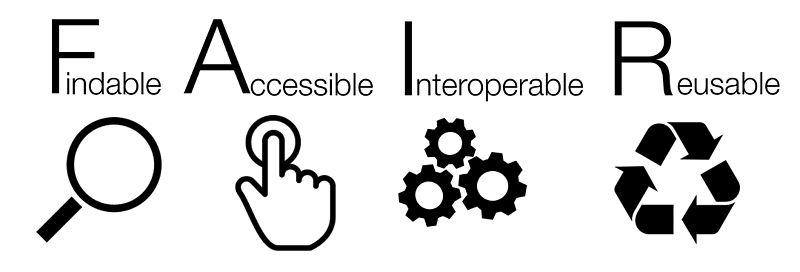
Für freie Forschungsdaten gibt es die sogenannten FAIR-Prinzipien. Diese formulieren Kriterien, nach denen Daten wirklich als „Findable, Accessible, Interoperable, and Re-usable“ bezeichnet werden können. Das heißt: auffindbar, zugänglich, interoperabel und wiederverwendbar. Diese Kriterien konnten für die Daten nicht vollständig umgesetzt werden. Sie haben noch immer keine dauerhafte Kennung („persistent Identifier“), sie sind nicht in einer allgemein anerkannten Sprache verfasst. Immerhin ist das eigene Datenformat, in dem die Daten codiert sind, gut beschrieben und dokumentiert. Sie sind aber in standardisierten Protokollen gespeichert (JSON und CSV) und über standardisierte Schnittstellen (HTTP, GIT) verfügbar. Außerdem erlaubt die freie Lizenz CC Zero ihre Weiternutzung.
Was wir gelernt haben
Nie wieder proprietäre Daten: Projekte, die auf die Erhebung und Veröffentlichung von Kulturdaten zielen, müssen von Beginn an möglichst nah an den FAIR-Prinzipien organisiert werden.
Offenheit: Daten sollten von vornherein auf Offenheit und Zugänglichkeit angelegt werden und nicht in verschlossenen technischen Systemen und hinter Lizenzschranken versteckt werden. Auch das dient der Lebensdauer digitaler Daten.
Dokumentation: Wenn man will, dass die Daten einen selbst überleben, dann muss man sie minutiös dokumentieren. Nur so können später Menschen unter veränderten technischen Rahmenbedingungen weiterhin mit ihnen arbeiten.
Haben Sie weitere Ideen für diesen Datenbestand? Sagen Sie uns in den Kommentaren, was wir mit den Daten machen sollten. Oder kommentieren Sie direkt im GitHub-Repository.
Danke für die Darstellung. Wer macht sich schon Gedanken darüber, was „hinter den Kulissen“ so alles passiert – oder passieren muss. Immerhin: Die Verantwortlichen sollten sich die erforderlichen Gedanken machen. Ich kann mir schon gut vorstellen, dass „damals“ von den Programmierern darauf hingewiesen wurde. Doch wollte man das hören?
Information re-retrieval oder Die sich selbst überholende Beschleunigung: Was für eine wiederkehrende Arbeitsleistung!
Lieber Herr Altenhein, danke für Ihren Kommentar: Sie haben Recht. Wer dachte, dass digitale Informationssysteme Probleme ein für allemal lösen und sich quasi von selbst erhalten, lernt nun, dass Datenerhalt eine dauernde Aufgabe ist. Wer wird sie übernehmen? Werden wir eigene Spezialist*innen für den Datenerhalt bekommen, so wie wir sie z. B. für Papiererhalt oder Gemälderestaurierung haben? Das wird spannend.