




KI-Projekt gewinnt Best Paper Award
Für ihre Teilnahme am Shared Task LLMs4Subjects gewinnen Lisa Kluge und Maximilian Kähler einen Best Paper Award. Dabei wurde die im KI-Projekt entstandene Publikation „DNB-AI-Project at SemEval-2025 Task 5: An LLM-Ensemble Approach for Automated Subject Indexing“ als bestes Paper unter allen Einreichungen für den Shared Task ausgezeichnet.
LLMs4Subjects
Das Leibniz-Informationszentrum Technik und Naturwissenschaften (TIB) hat einen Shared Task, eine Art Wettbewerb für die Wissenschaftscommunity, unter dem Titel LLMs4Subjects1 ausgeschrieben. Dabei geht es darum Ansätze zu entwickeln, die große Sprachmodelle für die automatische Beschlagwortung mit GND-Termen von digitalen Publikationen aus dem Bestand der TIB einsetzen. Die erste Phase des Wettbewerbs fand im Rahmen der jährlich veranstalteten internationalen Semantic Evaluation (SemEval)-Workshop-Reihe2 statt, bei der verschiedene Aufgabestellungen im Themenfeld der maschinellen semantischen Analyse ausgeschrieben werden.

Foto: DNB, Josephine Kreutzer
Foto: privat
In der Regel werden im Rahmen eines Shared Tasks Datensätze zum Training und zur Evaluation zur Verfügung gestellt und ergänzende Forschungsfragen gestellt. Beispiele für andere Shared Tasks bei SemEval sind etwa korrekte Übersetzung seltener oder ambiger „Named Entities“ (Orte, Personen usw.)3, oder das „Verlernen“ sensibler Daten, die große Sprachmodelle im Training „aufgeschnappt“ haben.
Teilnehmen können Teams oder Einzelpersonen aus Unternehmen, Universitäten, Bibliotheken oder anderen Einrichtungen. Die Ergebnisse der verschiedenen Abgaben werden auf einem sog. Leaderboard verglichen und es werden anschließend Berichte über die jeweilige Arbeit geschrieben und die Erkenntnisse im Rahmen des Workshops besprochen.
In der ersten Runde von LLMs4Subjects haben insgesamt 15 internationale Teams, u.a. aus Finnland, Estland, Deutschland, Italien, China und Iran teilgenommen.
Wie funktioniert die Beschlagwortung mit großen Sprachmodellen?
Prinzipiell gibt es verschiedene Wege, sich der Aufgabenstellung zu nähern. Spätestens durch die Popularität von ChatGPT und co. haben sicherlich schon viele Menschen große Sprachmodelle zumindest einmal ausprobiert. Man interagiert mit den großen Sprachmodellen über Prompts, also Textschnipsel, in denen man beschreibt, was das Sprachmodell für einen erledigen soll. So könnte man zum Beispiel verlangen: „Entwerfe eine Rede für die Geburtstagsfeier meiner Schwester.“ Das Modell würde daraufhin eine Antwort generieren. Sollte diese zufriedenstellend sein, so ist nichts weiter zu tun. Sollte man aber eine gänzlich andere Vorstellung des Ergebnisses haben, möchte man vielleicht nachbessern. Idealerweise kann man dem Sprachmodell ein wohlgelungenes Beispiel einer solchen Rede zur Verfügung stellen, was es als Orientierung verwendet. Die Anweisung könnte sich wie folgt verändern: „Entwerfe eine Rede für die Geburtstagsfeier meiner Schwester. Orientiere dich dabei an diesem Beispiel: BEISPIELREDE“. Da die Sprachmodelle darauf angepasst werden, dem Input des Users zu entsprechen, sollte man im Idealfall mit dieser näheren Spezifizierung bessere Chancen auf ein zufriedenstellendes Ergebnis haben.
Auf die automatische Beschlagwortung übertragen könnte man ebenso mit einer simplen Anweisung starten oder ebenfalls Beispiele mitliefern. Der Unterschied zum vorherigen Beispiel ist, dass zusätzlich zur Anweisung der zu beschlagwortende Text an das Sprachmodell übergeben werden muss. In Tabelle 1 sind zwei Beispiele für Publikationstitel gegeben, die man in einem Prompt verwenden könnte. Auf den ersten Blick fällt direkt auf, dass diese Beispiele sich deutlich in der Zahl der annotierten Schlagwörter unterscheiden. Während der erste Titel mit mehreren Schlagwortfolgen erschlossen ist, wurde der zweite Titel mit einem einzigen Schlagwort annotiert, welches außerdem im Titel direkt genannt wird. Im ersten Titel taucht wiederum der Begriff „Kalter Krieg“ auf, der sicherlich kein zutreffendes Schlagwort für die Publikation wäre.
| IDN | Titel | Schlagwörter |
| https://d-nb.info/115207881X | Der neue Kalte Krieg der Medien : Die Medien Osteuropas und der neue Ost-West-Konflikt | Deutschland; Massenmedien; Glaubwürdigkeit; Krise; Parteilichkeit; Debatte Ostmitteleuropa; Südosteuropa; Politischer Wandel; Medienpolitik Osteuropa; Massenmedien; Beeinflussung; Russland Russland; Medienpolitik Westliche Welt; Rechtspopulismus; Social Media; Falschmeldung; Meinungsfreiheit; Debatte Ost-West-Beziehungen; Feindbild; Massenmedien; Parteilichkeit |
| https://d-nb.info/1001046307 | Biomechanik : Grundlagenforschung und Anwendung : vom 3. – 4. April 2009 in Tübingen | Biomechanik |
Durch unsere Experimente haben wir herausgefunden, dass das Verwenden von Beispielen, sog. Few-Shot Demonstrationen, bessere Ergebnisse erzeugt, als eine Beschlagwortung ohne. Auch die genaue Zusammenstellung der Beispiele, wie die Anzahl der Beispiele oder die Menge der Goldlabels, kann die Beschlagwortung beeinflussen. Wenn in den Promptbeispielen pro Text besonders viele Schlagwörter annotiert sind, wie im ersten Beispiel in der obigen Tabelle, wird auch der Testtext durch das Sprachmodell tendenziell mit mehr Schlagwörtern versehen. Mit mehr sparsam annotierten Beispielen wie dem zweiten aus der Tabelle würde das Modell verhaltener reagieren und weniger Schlagwörter vorschlagen.

Abbildung 1 zeigt eine Übersicht der zwei zentralen Schritte unserer Beschlagwortung. Im ersten Schritt, „Complete“, werden durch ein sogenanntes Few-Shot-Prompting Verfahren freie Schlagwörter für einen zu beschlagwortenden Text erzeugt. Da diese Schlagwörter aber noch keinen GND-Entitäten entsprechen, ist der zweite Schritt, „Map“, erforderlich. Hier werden die freien Schlagwörter auf die nächstähnlichste GND-Entität über deren Vorzugsbenennung oder alternative Bezeichnungen projiziert. Das ist möglich über sogenannte Embeddings, also Vektorrepräsentationen, die für Wörter, Phrasen, Sätze oder andere Texteinheiten erzeugt werden können. Diese Embeddings werden auf Textdaten trainiert und bilden dann das Vokabular auf einen hochdimensionalen Vektorraum ab.
Wörter oder Phrasen mit gleicher oder ähnlicher Bedeutung werden in einem guten Embeddingmodell einen sehr ähnlichen Vektor haben.
Diesen Ansatz haben wir auch schon in einem Konferenzbeitrag letztes Jahr angewendet und uns bei der Untersuchung auf verschiedene Möglichkeiten der Promptzusammenstellungen und den Vergleich von LLM und klassischeren Methoden konzentriert4.
Was haben wir für den Wettbewerb angepasst?
Für die Teilnahme bei SemEval haben wir unser System noch erweitert und unsere Ergebnisse in dem als Best Paper prämierten Artikel veröffentlicht5.
Was wir für die Teilnahme an SemEval angepasst haben, ist unten in Abbildung 2 dargestellt.
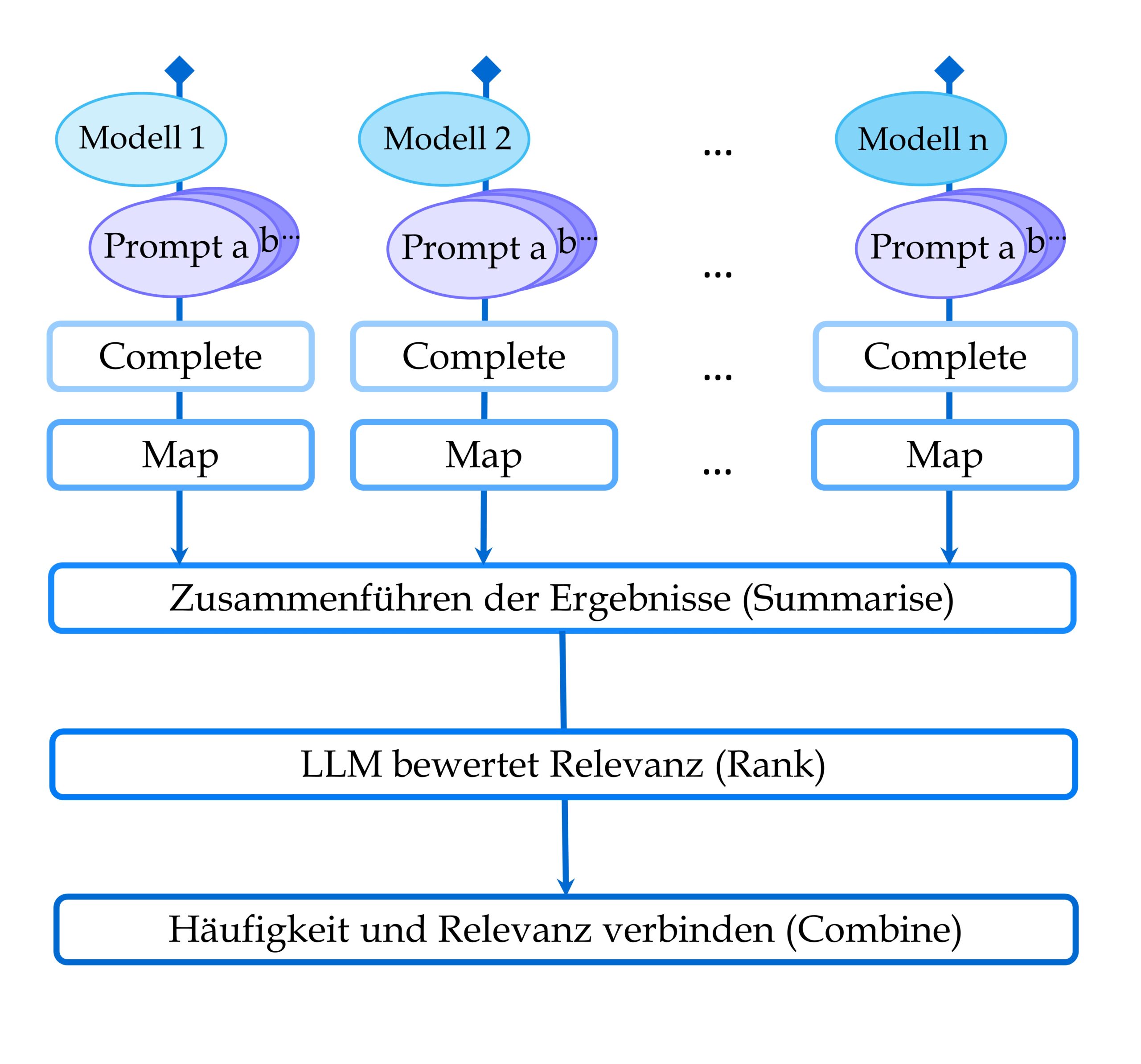
Wir haben unser Verfahren auf ein LLM-Ensemble ausgeweitet, indem wir die vorgestellten Schritte, Complete und Map, für mehrere Sprachmodelle und Prompts ausführen. Die Liste an getesteten Sprachmodellen ist in Tabelle 2 abgebildet.
| HuggingFace user | Modellname |
| meta-llama | Llama-3.2-3B-Instruct Llama-3.1-70B-Instruct |
| mistralai | Mistral-7B-v0.1 Mistral-7B-Instruct-v0.3 Mixtral-8x7B-Instruct-v0.1 |
| teknium | OpenHermes-2.5-Mistral-7B |
| openGPT-X | Teuken-7B-instruct-research-v0.4 |
Alle anschließenden Schritte dienen dem verfeinern, ordnen und ggf. aussortieren von Ergebnissen. Die Vorschläge der Modell-Prompt Kombinationen werden sozusagen in einen großen gemeinsamen Topf gekippt. Dabei wird gezählt, wie häufig welcher Vorschlag für ein bestimmtes Dokument gemacht wird. Über ein häufig auftretendes Schlagwort sind sich die Sprachmodelle einig, seltener vorkommende Schlagwörter sind spezieller, was sowohl positiv als auch negativ sein kann. Auch lassen wir die Menge der Schlagwörter mit einem anderen LLM nach ihrer Relevanz bewerten. Das LLM erhält einen Prompt, wo das Schlagwort und der Text, anhand dessen dieses Schlagwort generiert wurde, enthalten sind. Sollte durch einen vorherigen Schritt ein sehr unpassendes Schlagwort erzeugt worden sein, so ist diese Relevanzbewertung ein Mittel, seine Wichtigkeit zurückzustufen. In einem finalen Schritt wird ein gewichtetes Mittel aus der Häufigkeit und der Relevanz gebildet.
Mit diesem Ansatz haben wir ein Test-Set von ca. 28.000 Dokumenten beschlagwortet und haben unsere Ergebnisse mit denen von 14 anderen Teams bei LLMs4Subjects verglichen.
Die Ergebnisse des Shared Tasks
Die Ergebnisse von LLMs4Subjects sind im Leaderboard veröffentlicht. Die Auswertung erfolgte in zwei Modi: Beim quantitativen Vergleich, wurden die Ergebnisse jedes Teams direkt mit den von der Inhaltserschließung der TIB nach RSWK als Goldstandard annotierten Schlagworten verglichen. Bei der qualitativen Evaluation hat die Inhaltserschließung der TIB direkt die maschinellen Vorschläge der Teams in kleinen Stichproben hinsichtlich ihrer Nützlichkeit bewertet.
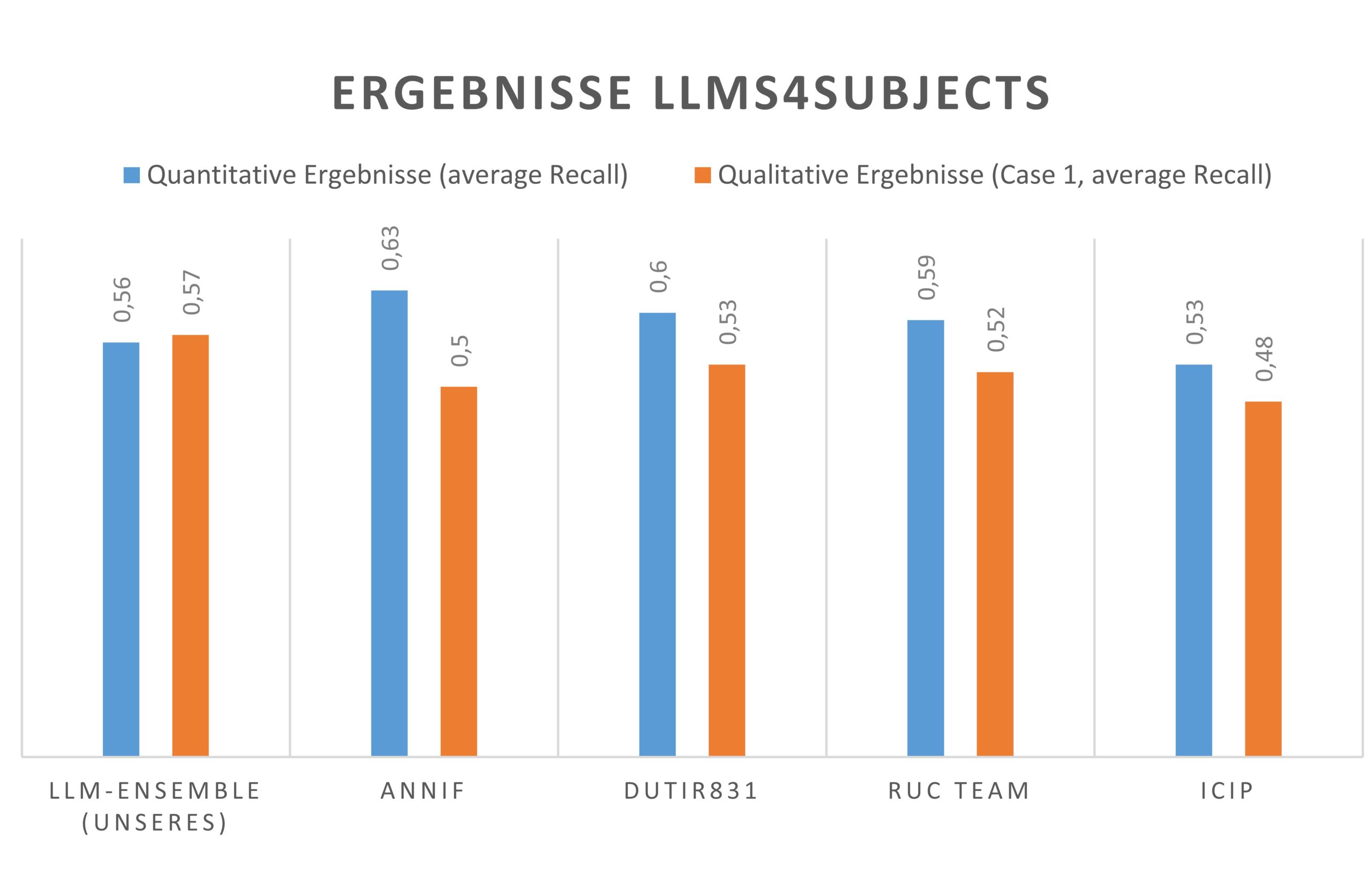
Abbildung 3 zeigt die Ergebnisse von den 5 Teams, die in der allgemeinen quantitativen Evaluation am besten abgeschnitten haben. In der reinen quantitativen Auswertung, also dem reinen Abgleich der Ergebnisse mit dem Goldstandard, belegen wir den vierten Platz. In der qualitativen Auswertung liegen wir sogar knapp vorne. Das bedeutet, dass unser System, auch wenn es nicht optimal den Goldstandard nach RSWK wiedergibt, sehr hilfreiche Vorschläge produziert.
Unter den weiteren Teilnehmenden des Shared Tasks ist auch das Annif-Team der finnischen Nationalbibliothek, welches das gleichnamige Annif-Toolkit6 veröffentlicht hat. Annif belegt im quantitativen Ranking den ersten Platz. Das Toolkit wird auch in der DNB in der Erschließungsmaschine verwendet, um die automatische Beschlagwortung im produktiven Betrieb durchzuführen. Perspektivisch arbeiten wir daran Erkenntnisse aus dem KI-Projekt in Annif zu integrieren, und diese so einer größeren Community zur Verfügung zu stellen.
Der Prototyp für das LLM-Ensemble aus dem KI-Projekt steht Open-Source unter Github zur Verfügung.
Ausblick
Aktuell befindet sich der Shared Task LLMs4Subjects in einer zweiten Runde. Dabei wird das Thema „Ressourcen & Effizienz“ gezielt in den Mittelpunkt gestellt. Auch diesmal hat das DNB-KI-Projekt Ergebnisse eingereicht, die im September im Rahmen der KONVENS-Konferenz veröffentlicht werden.
- J. D’Souza, S. Sadruddin, H. Israel, M. Begoin und D. Slawig, SemEval-2025 Task 5: LLMs4Subjects–LLM-based Automated Subject Tagging for a National Technical Library’s Open-Access Catalog, arXiv preprint arXiv:2504.07199, 2025. ↩︎
- „SemEval,“ 2025. [Online]. Available: https://semeval.github.io/. [Zugriff am 06 05 2025]. ↩︎
- S. Conia, M. Li, R. Navigli und S. Potdar, „SemEval 2025 Task 2: Entity-aware machine translation,“ Proceedings of the 19th International Workshop on Semantic Evaluation (SemEval-2025), 2025. ↩︎
- L. Kluge und M. Kähler, „Few-Shot Prompting for Subject Indexing of German Medical Book Titles,“ in Proceedings of the 20th Conference on Natural Language Processing (KONVENS 2024), Vienna, Austria, 2024. ↩︎
- L. Kluge und M. Kähler, „DNB-AI-Project at SemEval-2025 Task 5: An LLM-Ensemble Approach for Automated Subject Indexing,“ in Proceedings of the 19th International Workshop on Semantic Evaluation (SemEval-2025), Vienna, Austria, 2025. ↩︎
- J. I. M. L. Osma Suominen, „Annif and Finto AI: Developing and implementing automated Subject Indexing,“ JLIS.it, Bd. 13, Nr. 1, p. 265–282, 2022. ↩︎