




DNBVIS_frodiss
Als Deutsche Nationalbibliothek bieten wir unsere freien digitalen Objekte und Daten bereits seit längerem zur Nachnutzung auf verschiedenen Wegen an, beispielsweise über Schnittstellen oder als Download von Datensets über unsere Webseite. In den letzten Jahren wuchs dabei das Interesse von Wissenschaft und Forschung und insbesondere das der Digital Humanities an diesen Daten stetig, denn sie können neue Erkenntnisse zu verschiedensten wissenschaftlichen Fragestellungen ermöglichen. Visualisierungen eignen sich dabei besonders gut, um schnell einen Einstieg oder Überblicke zu bestimmten Themen zu erhalten – ein Thema, dass daher auch uns als DNB immer stärker beschäftigt.
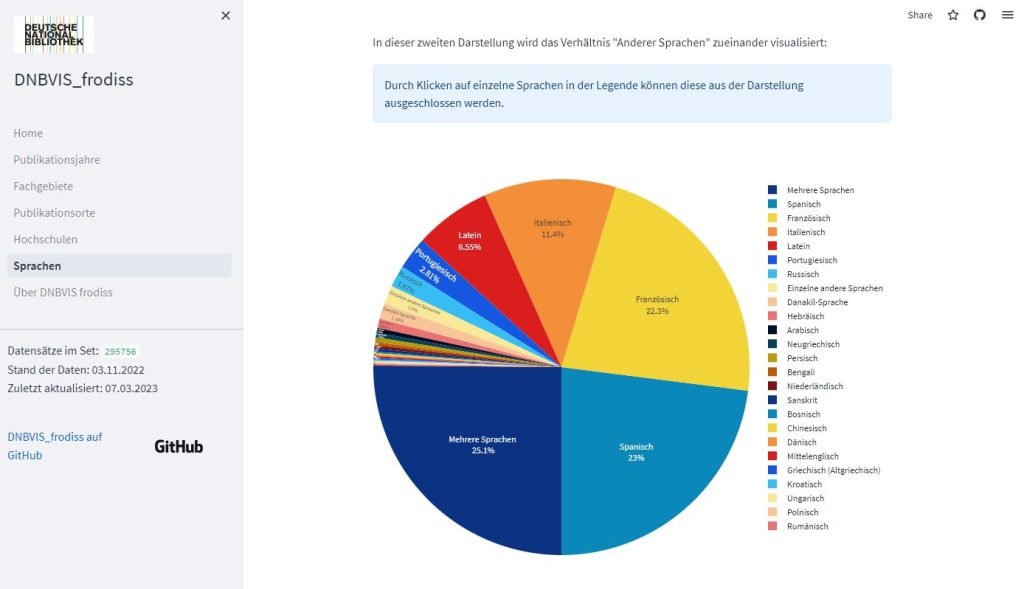
Mit DNBVIS_frodiss ist nun eine exemplarische Anwendung entstanden, die durch verschiedene Visualisierungen einen Einstieg in unser Datenset der „Freien Online-Hochschulschriften“ bietet. Dabei wurde das Set nach verschiedenen Fragestellungen aufbereitet: Wie gestaltet sich beispielsweise der Zuwachs an frei zugänglichen, elektronisch verfügbaren Hochschulschriften seit 1990 an der DNB? An welchen Hochschulen sind diese entstanden oder veröffentlich worden? Und wie verteilen sich die Hochschulschriften auf unterschiedliche Fachgebiete? Zusätzlich stellt die Anwendung verschiedene Links auf das Portal der DNB bereit, so dass die Möglichkeit besteht, die hinter den verschiedenen Visualisierungen liegenden Titeldaten zu durchstöbern.
Eine Herausforderung war wie bei anderen Datenanalysen das methodische Vorgehen sowie die vorab zu leistende Datenbereinigung: Die Erfassungsregeln für Bibliotheken haben sich über die Jahre zum Teil mehrfach geändert und obwohl viel Arbeit in entsprechende Anpassungen geflossen ist, spiegeln die Daten noch immer einige dieser historischen Prozesse wieder, die bei der Auswertung natürlich berücksichtigt werden müssen. Zudem sind in den Datensätzen viele Informationen enthalten, die nicht normiert, sondern als Freitext erfasst wurden – sollen auch diese Informationen ausgewertet werden, muss daher zunächst dafür gesorgt werden, dass diese Daten auch inhaltlich verlässlich so vorliegen, dass sie einheitlich analysiert und ausgewertet werden können.
Ein einfaches Beispiel hierfür ist bereits die Erfassung des Publikationsjahres: Je nach Angabe in der entsprechenden Publikation kann hier eine Jahreszahl wie bspw. „2010“ stehen, unter bestimmten Umständen steht diese Jahreszahl aber auch in eckigen Klammern „[2010]“ oder wird von einem ©-Zeichen angeführt („©2010“). Neben diesen Unterschieden in den Daten, die durch Angaben in den Publikationen selbst sowie die Umsetzung der Erschließungsregeln bedingt sind, gibt es aber auch noch den ganz klassischen Tippfehler, der zwar glücklicherweise nur sehr selten vorkommt, aber durch den aus dem Publikationsjahr „2010“ auch schnell einmal das Jahr „20110“ werden kann. In einem solchen Fall kann dann das Datum auch leider nicht immer durch einen passenden Algorithmus korrigiert werden, denn ob mit 20110 nun 2010 oder doch eher 2011 gemeint war, ist zunächst nicht eindeutig auflösbar. Finden sich keine weiteren Hinweise auf das korrekte Datum direkt im Datensatz, muss die entsprechende, in diesem Fall digitale Publikation ganz analog und vor allem manuell herausgesucht und das Publikationsdatum überprüft werden.
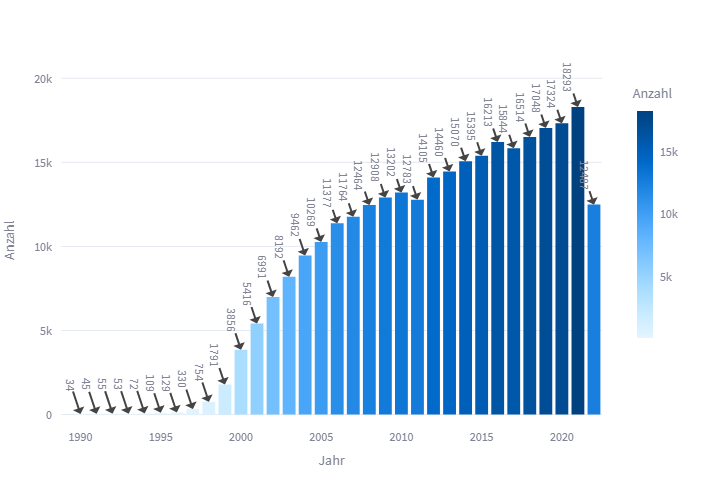
Auch DNBVIS_frodiss musste sich in seiner Entwicklung natürlich diesen Schwierigkeiten stellen und nicht immer gab es wirklich eindeutige oder zufriedenstellende Lösungen. Um das Vorgehen und die Präsentation der Daten transparent zu halten, wird daher in jedem Abschnitt kurz geschildert, wie die vorliegende Visualisierung erstellt wurde. Ebenfalls wird darauf eingegangen, ob Daten bereinigt wurden und ob bestimmte Teile der Daten für eine Darstellung keine Berücksichtigung fanden. Dies war beispielweise bei der Erstellung der Übersicht der freien Online-Hochschulschriften nach Publikationsjahren der Fall, da hier alle Hochschulschriften unberücksichtigt blieben, die vor 1990 publiziert worden waren. Diese Entscheidung wurde vor allem im Sinne der Übersichtlichkeit getroffen, da es sich bei den unberücksichtigten Datensätzen nur um eine kleine Anzahl handelte, deren Einbezug in die Darstellung die Visualisierung allerdings deutlich weniger übersichtlich gestaltet hätte. Die Skripte zu DNBVIS_frodiss sowie die für die Darstellungen genutzten, bereinigten Daten sind auf Github verfügbar.
DNBVIS_frodiss bietet den Nutzer*innen einen ersten Einstieg in ein spezifisches Datenset der DNB, welches exemplarisch zeigt, welche Fragestellungen an unsere Daten gerichtet und wie diese visuell präsentiert werden können. Die Anwendung zeigt mit wenigen Klicks schnell und intuitiv, wie sich der Zuwachs freier Online-Hochschulschriften historisch entwickelt hat und welche Fachbereiche bereits sehr häufig in dieser Form publizieren. Auch die relative geographische Verteilung auf Hochschulen sowie Publikationsorte lässt sich schnell und einfach erkennen und kann miteinander verglichen werden. Die Vermutung liegt nahe, dass Publikationsort und Ort der für die Hochschulschrift hauptverantwortlichen Hochschule gerade bei digitalen Hochschulschriften durch Veröffentlichungen in hochschuleigenen Repositorien weitestgehend identisch sein dürfte, doch ließe sich dies in einem nächsten Schritt prüfen. So schließen sich viele weitere mögliche Fragen an das Datenset an, die Auskunft über das Publikationswesen freier Hochschulschriften in Deutschland sowie dessen Entwicklung geben und die zukünftig durch weitere Analysen beantwortet werden können.

Neben dem Potential, welches die Aufbereitung, Analyse und Visualisierung bibliothekarischer Daten für Wissenschaft und Forschung bietet, sind solche Visualisierungen natürlich auch für Bibliotheken selbst interessant. Sie können damit ihre eigenen Bestände besser kennenlernen und Einblicke erhalten, die ohne die Darstellung großer Datenmengen auf diese Art nicht möglich sind. Und nicht zuletzt bieten Visualisierungen eine einfache und gut nutzbare Möglichkeit, Unstimmigkeiten oder Fehler in den Daten, wie bspw. das bereits erwähnte Publikationsjahr „20110“, zu identifizieren und nachträglich zu bereinigen und können so auch zur Verbesserung der Datenqualität genutzt werden.
DNBVIS_frodiss ist somit als Anregung und Einstieg zur Beschäftigung mit unseren Daten zu verstehen, denn diese bieten vielfältige Anwendungs- und Analysemöglichkeiten. Eine Weiterentwicklung der Anwendung ist vorgesehen, und so freuen wir uns über Kommentare, Fragen und Feedback jeglicher Art oder auch auf neue Ideen! Antworten Sie dazu gerne einfach auf diesen Blogpost oder schreiben Sie direkt an s.palek@dnb.de.
Sollten Sie selbst mit unseren Daten bereits gearbeitet haben oder dies in der Zukunft vorhaben, dann freuen wir uns über ihren Kontakt. Wir sammeln zudem Beispiele zur Analyse unserer Daten in der Praxis und unterstützen Sie gerne bei ihren eigenen Projekten. Wenden Sie sich hierfür an lab@dnb.de. Ergänzende Informationen finden Sie auf unserer DNBLab-Webseite.
Stephanie Palek ist Referentin für Digitale Dienste an der Deutschen Nationalbibliothek. Ihre Schwerpunkte liegen in den Bereichen Persistent Identifier und Endnutzerdienste insbesondere im Bereich forschungsnaher Dienstleistungen und der Visualisierung.Stephanie Palek